GPT-5.5 is here. The internet has thoughts.
By Tijo Gaucher & Annaki Nguyen · Human+AI

- Shipped:April 23, 2026 in ChatGPT & Codex; API live April 24. Codename “Spud.”
- Real bugs caughtin code review: 58.3% → 79.2% (+20.9 pt).
- Precision: 27.9% → 40.6% (+12.7 pt). Less noise on PRs.
- Token economy: ~half the tokens per agent step → ~2.4× more retries inside the same budget.
- Watch out for: indigo/violet UI bias, prompts followed too literally, polished but unoriginal output.
- Verdict for SMEs: switch — for scoped, real work. Architecture taste is still on you.
OpenAI shipped GPT-5.5 — internal codename “Spud”— on April 23, 2026. The framing on the OpenAI blog calls it a “new class of intelligence.” The framing in our timeline calls it incremental. Both are right, depending on which job you're asking it to do.
Underneath the marketing, this is the biggest jump in developer-workflow signal we've seen in a release this year. Below: the receipts, the quiet feature nobody put on a slide, the four quirks worth knowing, and the verdict for any small or mid-sized team trying to decide whether to flip the switch this week.
What changed with GPT-5.5
GPT-5.5 is the first fully retrained base model since GPT-4.5, natively omnimodal, and it leads every publicly available model on Terminal-Bench 2.0 at 82.7%— the benchmark that measures whether a model can actually finish a multi-step coding task at the command line, not just write a snippet. It rolled out to ChatGPT Plus, Pro, Business, and Enterprise on April 23, with API access for GPT-5.5 and GPT-5.5 Pro arriving April 24. It also shipped inside Codex.
The headline is not “new class of intelligence.”The headline is: it's noticeably better at finding real bugs, while saying less to do it.
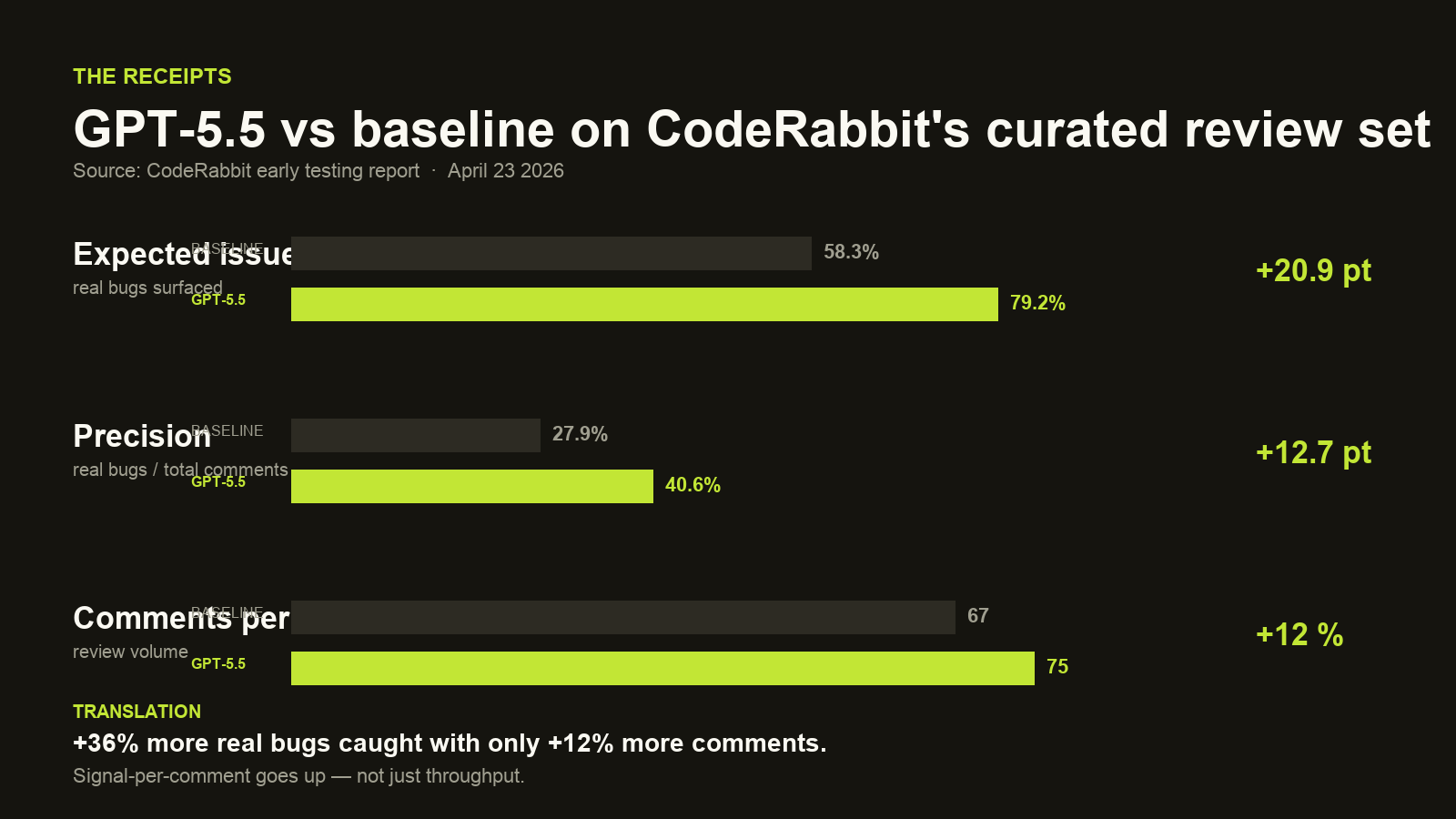
The CodeRabbit receipts
CodeRabbit — the AI code review platform — ran the new model on a curated review benchmark and published the numbers the day GPT-5.5 dropped. The shape of the result matters more than any single percentage:
- Expected issues found: 58.3% → 79.2%— a +20.9-point jump on real bugs surfaced.
- Precision: 27.9% → 40.6%— +12.7 points. When it speaks up, it's right more often.
- Comments per PR: 67 → 75— +12% more output, but with a much higher hit-rate.
Translation: +36% more real bugs caught with only +12% more comments. The model isn't just throwing more text at the problem — signal-per-comment is up. That's the harder thing to move, and that's where 5.5's advantage actually lives.
The quiet feature nobody's talking about
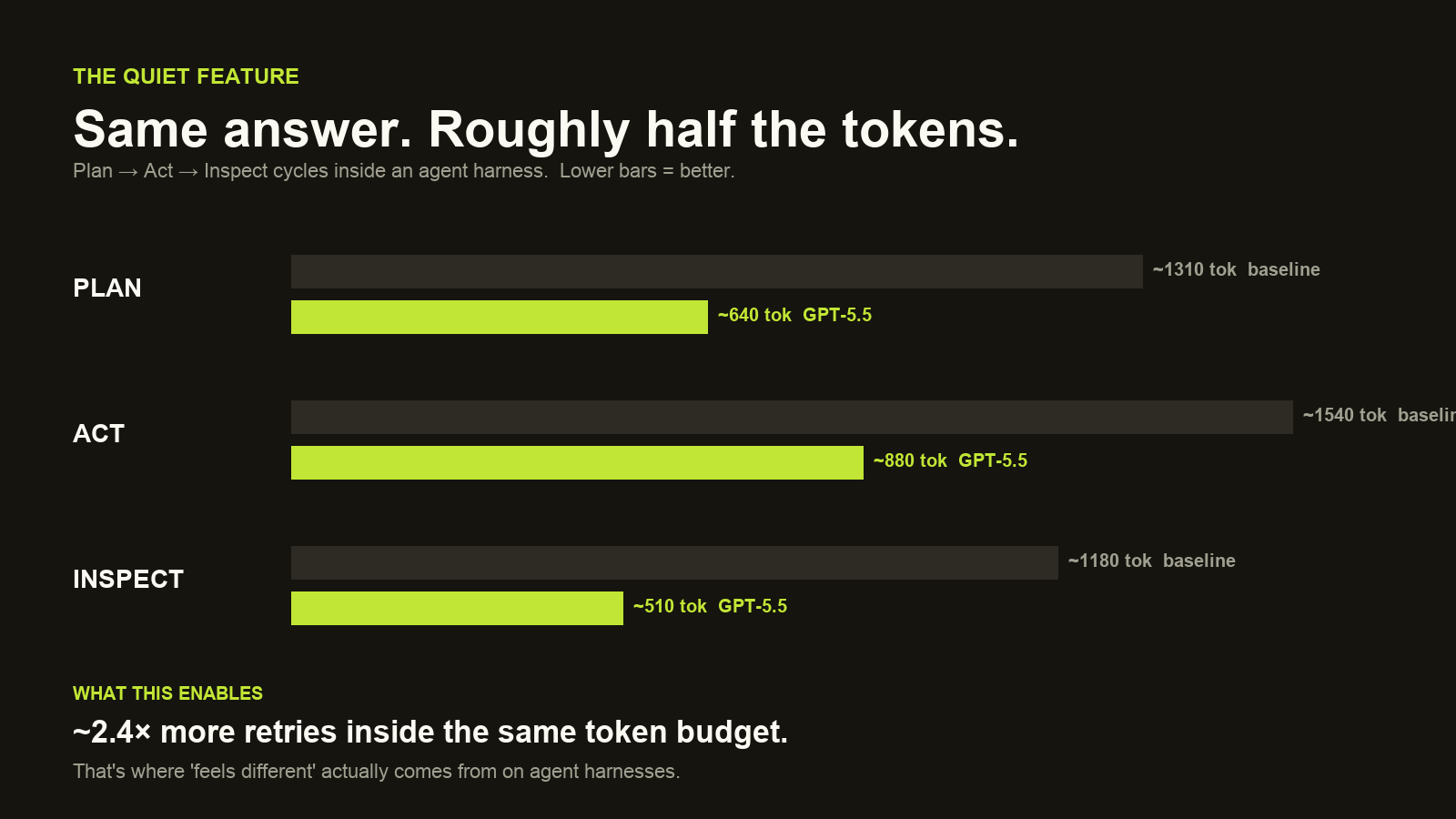
The press release leans on the headline benchmarks. The thing that actually shifts your day-to-day is the token economy.
On agent harnesses doing plan → act → inspect → retry loops, GPT-5.5 uses roughly half the tokens per step compared to the verbose 5.x baseline. Plan tokens drop from ~1,310 to ~640. Act tokens drop from ~1,540 to ~880. Inspect tokens drop from ~1,180 to ~510.
Practically: inside the same fixed token budget, you can now run about 2.4× more retriesbefore the budget runs out. For anyone running coding agents, browser-automation agents, or scheduled jobs against the OpenAI API, that's a real money number, not a benchmark footnote. It's the reason 5.5 “feels different” long before you read a release blog.
Voices from the timeline
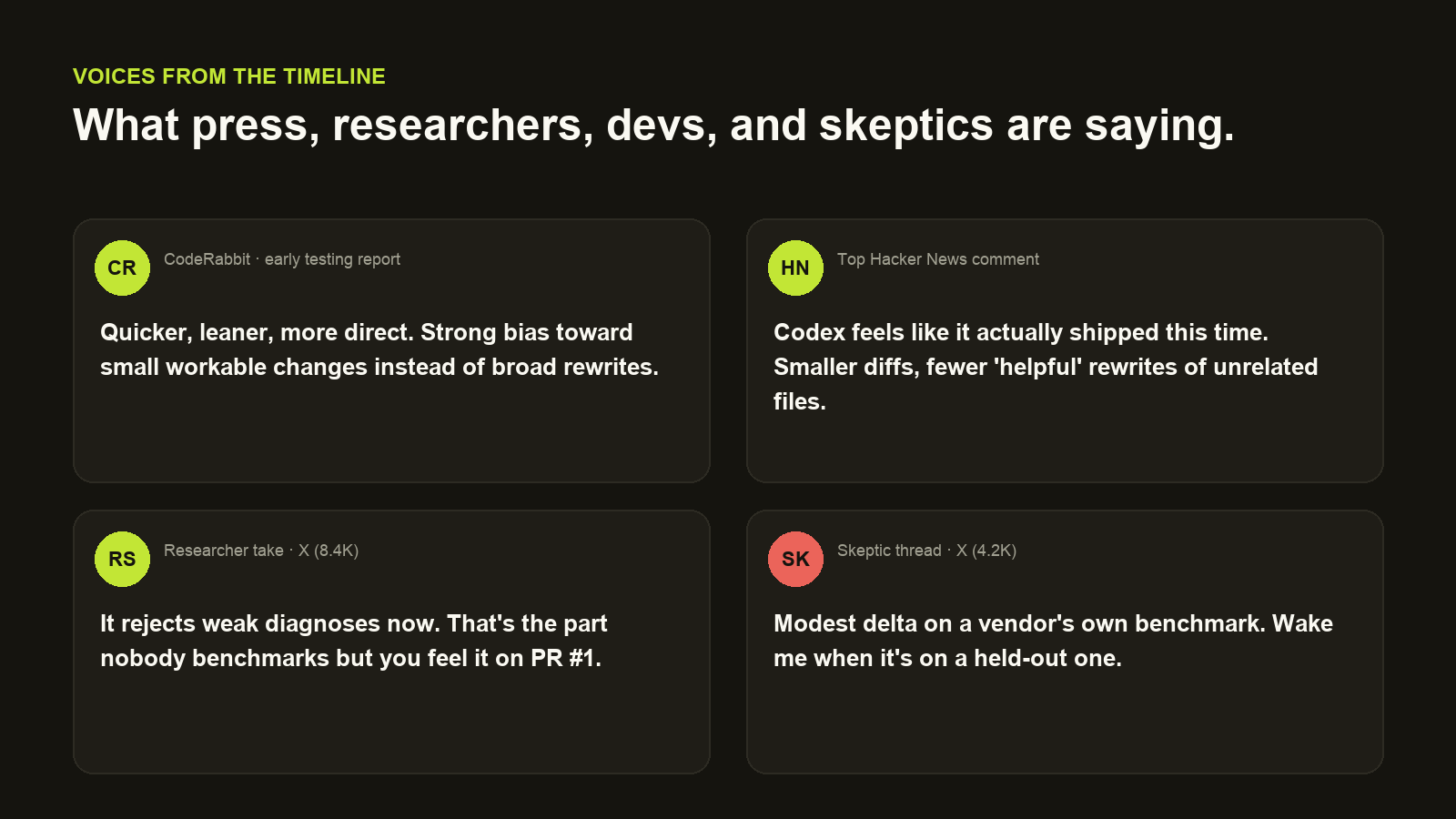
The early consensus is unusually convergent for an OpenAI release week. The honest people from each camp are saying basically the same thing in different vocabulary:
- CodeRabbit (early testing): “Quicker, leaner, more direct. Strong bias toward small workable changes instead of broad rewrites.”
- Top Hacker News thread: “Codex feels like it actually shipped this time. Smaller diffs, fewer ‘helpful’ rewrites of unrelated files.”
- Researcher take on X: “It rejects weak diagnoses now. That's the part nobody benchmarks but you feel it on PR #1.”
- Skeptic camp:“Modest delta on a vendor's own benchmark. Wake me when it's on a held-out one.” A fair line. Worth noting that Terminal-Bench 2.0 isn't OpenAI's benchmark — that one's independent.
Four quirks worth knowing
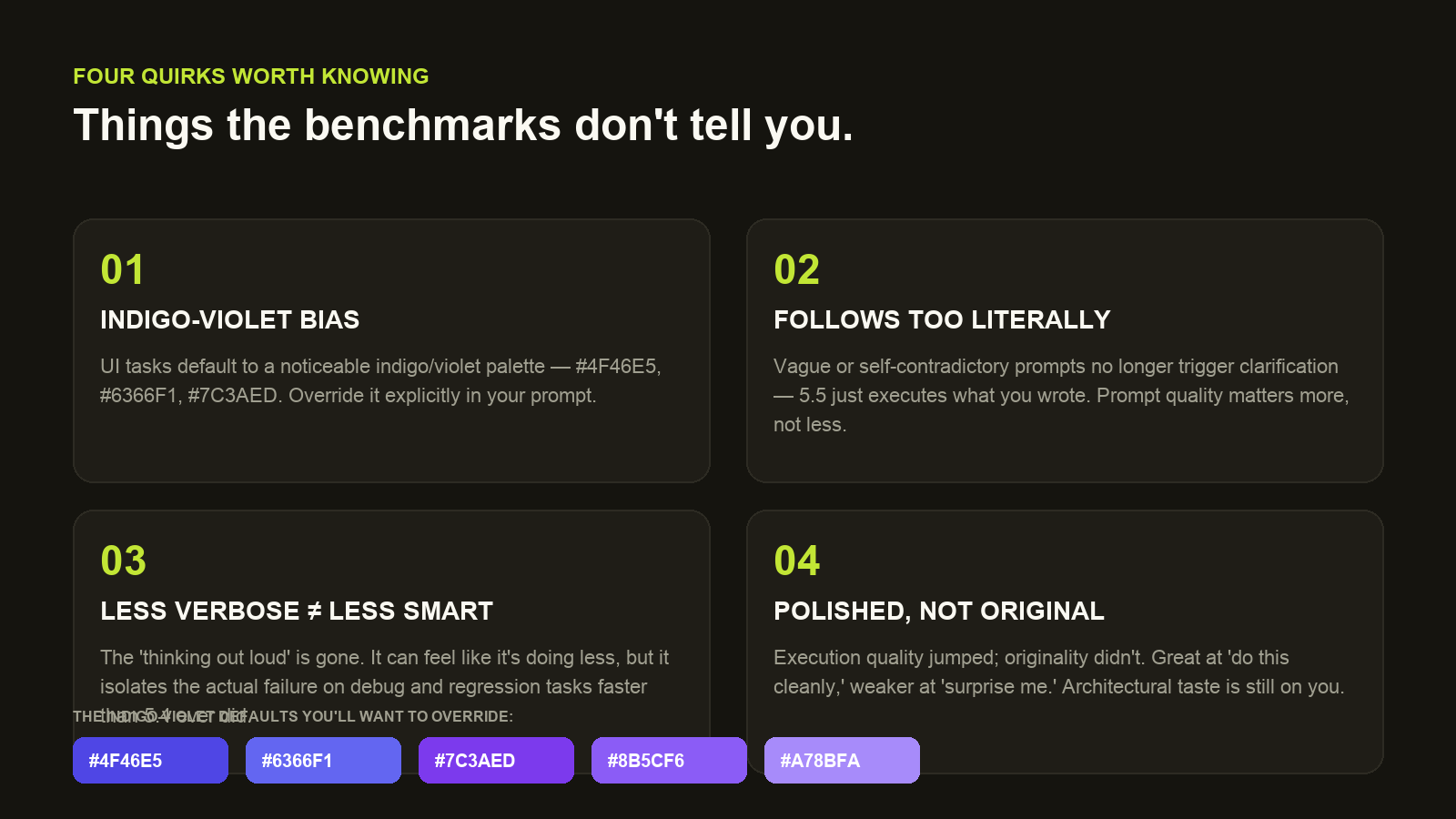
1. The indigo-violet default
On UI tasks, GPT-5.5 produces unusually polished interaction work and detailed animations — but it defaults to a noticeable indigo/violet palette (#4F46E5, #6366F1, #7C3AED, #8B5CF6). OpenAI's own design playbook flags “avoid purple-on-white defaults” for a reason. Override it explicitly in your prompt or your product is going to look like every other AI-generated SaaS landing page from the last six months.
2. It follows weak prompts too literally
When the prompt is vague, contradictory, or under-specified, 5.5 doesn't pause to clarify the way 5.4 sometimes did. It just executes — fast — and the output mirrors your prompt's weaknesses. Prompt quality matters more now, not less.If you've been getting away with sloppy briefs, this is the release where you'll feel it.
3. Less verbose ≠ less smart
The “thinking out loud” padding is gone. On a quick demo it can feel like 5.5 is doing less work. On real debug, access-control, and API-regression tasks it's the opposite — it isolates the actual failure and proposes a scoped fix faster than 5.4 ever did. Don't confuse fewer words for less judgment.
4. Polished, not original
Execution quality jumped. Originality didn't. Ask 5.5 to ship something cleanly and it will. Ask it to surprise you and it falls back on familiar styling, familiar architecture, familiar metaphors. Architecture-level taste is still a human load-bearing element. Don't outsource it to the model and then complain it all looks the same.
Should you switch? The verdict.
Yes — for scoped, real work.
Give GPT-5.5 a bounded task, explicit constraints, and a way to verify its output against the real system. It will out-execute the previous baseline on three things that compound across a quarter: review signal on every pull request, code-fix scope on every bug, and token economy on every agent loop. Those three are exactly the loops most SMEs are spending real money on.
For the harder things — original product strategy, architecture decisions, creative judgment — the human is still the load-bearing element. The model just got a lot better at executing the decisions you make. That's good news for anyone trying to do more with a small team. It's also a reminder that a sharper tool punishes a vague brief.
What to do this week (if you run an SME)
- Move your code review— if you're using an automated reviewer like CodeRabbit, Greptile, or CodiumAI, switch the underlying model to GPT-5.5 and re-run last week's merged PRs. Diff the comments. The +20.9 points is yours to claim, not just to read about.
- Audit your agent prompts for vagueness. The literal-execution behavior means any sloppy phrasing in your existing prompts is now actively hurting output. Tighten them.
- Override the color palette.If you're using 5.5 for UI generation, hard-code your brand colors in the system prompt. Otherwise enjoy your Indigo Phase.
- Re-cost your agent budgets.The token economy shift means your existing per-task budgets are now over-provisioned. That's either margin you can capture or retries you can buy — either way, recalculate.
That's the bet Human+AI is built on: every model release is a hand-off opportunity. Pick one workflow this week, hand it to 5.5, and ship. The teams that compound those weekly hand-offs through 2026 are the ones who'll spend 2027 extending leads, not catching up.
Want a GPT-5.5-powered agent running inside your business this month?
Human+AI is powered by Rapidclaw— we design and ship managed agentic workflows for SMEs. No API keys to wire up, no model selection to second-guess. We pick the right model (often 5.5, sometimes not), run the loop on reliable infrastructure, and hand you a thing that just works.
See what Rapidclaw buildsKeep reading
Sources
- OpenAI — Introducing GPT-5.5 (official launch post)
- CodeRabbit — GPT-5.5 benchmark results (curated review set)
- OpenAI — GPT-5.5 System Card (Deployment Safety Hub)
- TechCrunch — OpenAI releases GPT-5.5
- The New Stack — “A new class of intelligence” framing
- VentureBeat — Terminal-Bench 2.0 results (82.7%)
- OpenAI Developers — UI design playbook (the source of the “avoid purple-on-white defaults” guidance)
- Axios — OpenAI releases “Spud”